

44·
1 month agoIt’s supposed to be a dot (.) character. The project’s name is n.eko.

It’s supposed to be a dot (.) character. The project’s name is n.eko.
And replaced the word “AI” with “Apple”. ( ͡° ͜ʖ ͡°)

Umm, that is quite literally hallucinations what you are describing? Am I missing something here?
All models hallucinate, it’s just how language models work.
Do you have sources for this claim that Mistral’s models are trying to deceive anyone?
Prediction: This change comes to life, people make an uproar about this. Then they forget this in a few days and continue using reddit.
This same old keeps happening with reddit, Twitter/X, etc.
Hopefully we do receive some refugees to Lemmy!
Squid games reference. (or from one of the knockoff’s)
I’m not advocating for breaking any rules, but many people dont know that you can hide your wifi routers SSID. even fewer people know how to track these networks.
This is a bit off-topic, but did you try to increase the JVM limits inside Yacy’s administration panel?
This setting located in /Performance_p.html-page for example gives the java runtime more memory. Same page also has other settings related to ram, such as setting how much memory Yacy must leave unused for the system. (These settings exist so people who run Yacy on their personal machines can have guaranteed resources for more important stuff)
Other things that would reduce memory usage is to limit the concurrency of the crawler for example. There’s quite a lot of tunable settings that can affect memory usage. Would recommend trying to hit up one of the Yacy forums is also good place to ask questions. The Matrix channel (and IRC) are a bit dead, but there are couple of people including myself there!
Also, theres new docs written by the community, they might help as well! https://yacy.net/docs/ https://yacy.net/operation/performance/
Yes, I mentioned Kagi because of the Teclis search index is hosted by them.
However, most of the search results in Kagi are aggregated from dedicated search engines. (such as, but not limited to: Yandex, Brave, Google, Bing, etc.)
Teclis - Includes search results from Marginalia, free to use at the moment. This search index has been in the past closed down due to abuse.
Kagi, whose creation Teclis is, is a paid search engine (metasearch engine to be more precise) also incorporates these search results in their normal searches. I warmly recommend giving Kagi a try, it’s great, I’ve been enjoying it a lot.
–
Other options I can recommend; You could always try to host your own search engine if you have list of small-web sites in mind or don’t mind spending some effort collecting such list. I personally host Yacy [github link] (and Searxng to interface with yacy and several other self-hosted indexes/search engines such as kiwix wiki’s.). Indexing and crawling your own search results surprisingly is not resource heavy at all, and can be run on your personal machine in the background.
Kagi is a metasearch-engine (apart from their homebrew small-web index, known as Teclis), so the reddit lenses will continue to function long as one of the search engines it’s querying is paying reddit.
Hi!
Great question! I don’t crawl reddit, but this applies to other large sites as well. reddit themselves they have at this very moment banned the ip range where I host my Yacy at (Hetzner). I just looked up from my index that I do have 257k pages indexed from reddit through teddit I used to run, this is from before reddit api-enshittification, going to delete those right now.
And the way how the crawling is done is you define crawling depth, which limits how much content is crawled from the site.
… etc.
I have my tampermonkey scripts set to only crawling depth of 1 at the moment (Just set them to 2 actually, kinda curious how much more I will be crawling), I’ve manually crawled some local news sites as a curiosity at the beginning. And my database is currently relatively small, only around ~86.38 gigabytes according to Yacy. This stores aproximately 2.6 million documents in Yacy’s Solr.
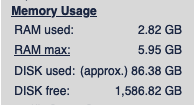
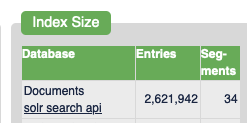
–
Yacy has tons of options for crawling, so you can customize how much it crawls and even filter out overly large sites with maximum number of documents set when you send Yacy there.

–
The tampermonkey script I’ve been talking about in these posts, it’s very simple script: https://github.com/JeremyRand/YaCyIndexerGreasemonkey
Hit me up if you guys have more questions! I’m by no means an expert on Yacy, but I will do my best to answer.
Surprisingly, it’s very doable, requires basic technical knowledge and relatively minimal computing resources (runs in the background on your computer).
I have tampermonkey script that sends yacy to crawl any websites that I visit, and it’s keeping up relatively good index for personal use of the visited websites. Combine yacy with ~300gb of Kiwix databases, add searxng as a frontend and you have pretty strong self hosted search engine.
Of course you need to supplement your searches from other search engines, as yacy does not crawl the whole web, just what you tell it to.
I encourage anyone who’s even slightly interested on this stuff to try Yacy, it’s ancient piece of software, but it still works very well and is not an abandoned project yet!
–
I personally use Yacy mostly on private mode, but it does have the distributed network there as well. 
They’re likely trying to mitigate ddos attack, resulting in this problem. I’m just guessing here tho.
https://status.kagi.com/